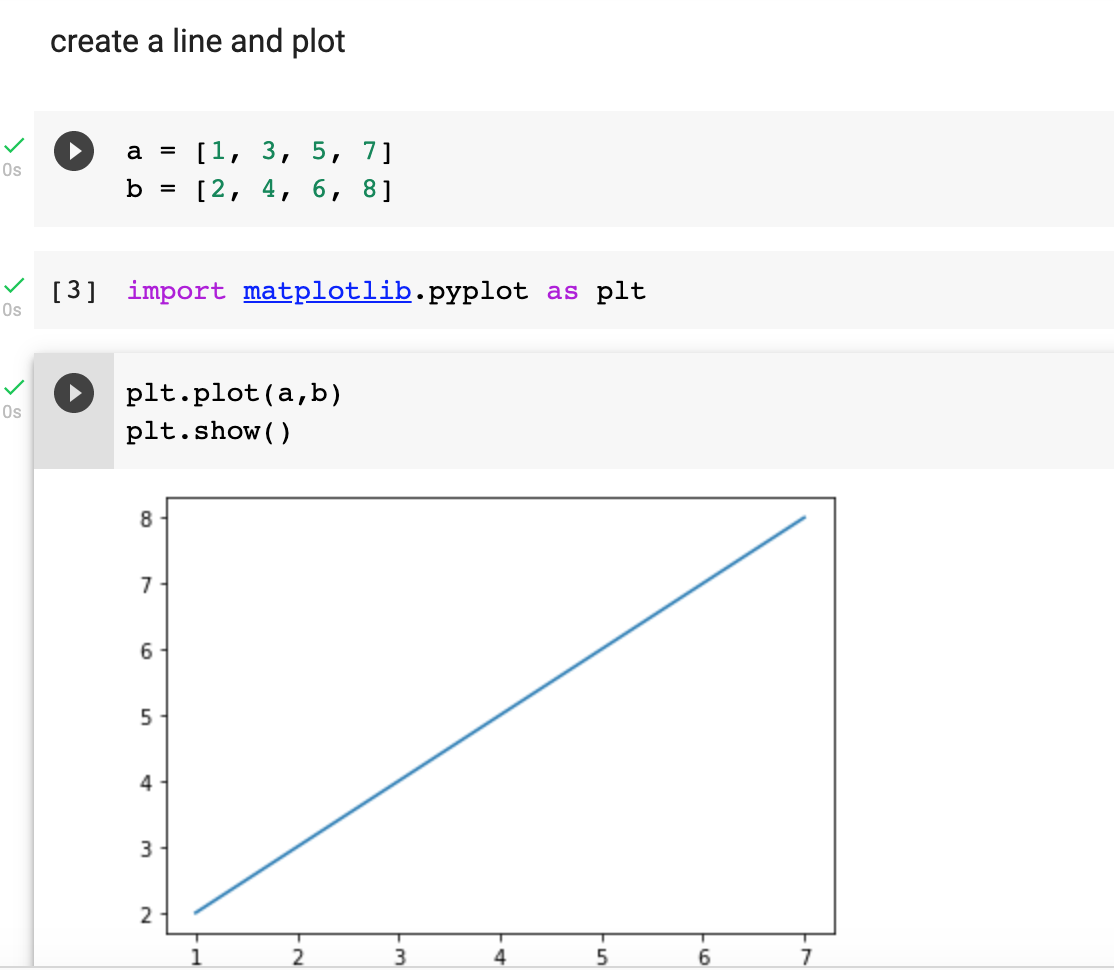
2주차 이번 강의는 내가 원하던 기본적인 명령어들이 많아서 좋다. 평소에 막힐 때 마다 검색해서 귀찮았는데, 이번에 한 번에 정리해두는 것 같아서 좋다. 아래 2주차 내용도 구글 colab 의 ipython 링크에 저장해두었다. 아래 메모는 "치트시트" 처럼 눈으로 훑으면서 전체적인 내용을 파악하는데 도움이 된다. 정확히 파악하려면 ipython 연습 코드를 참조할 필요가 있다. Lists and Tuples Tuples 콤마와 괄호로 이루어져있다. 예: score = (5, 4, 3, 5, 2, 4, 3, 5) tup = ('dance', 5, 2.4) type(tup) = tuple tup[0]: 'dance' tup[2]: 2.4 tup[-2]:5 new_tup = tup + ('sing', 3.5..