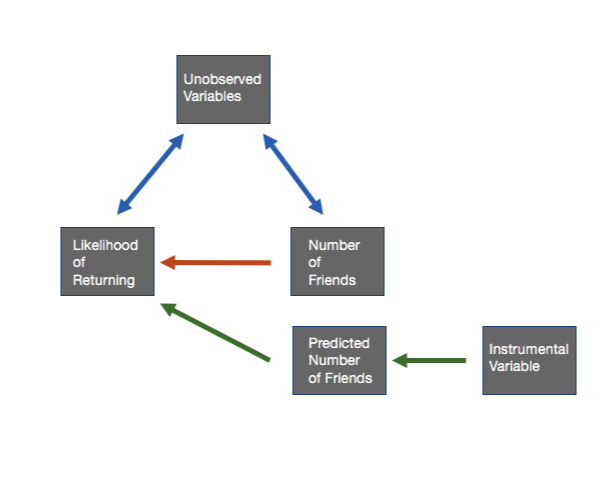
Chapter 22. Leakage and Interference between Variants 인트로 키워드: “spillover” (leakage, interference) [발표자: 책에서 세 가지 용어를 혼용해서 사용한다는 인상을 받았다] 특정 유닛의 행동에 다른 unit 이 영향을 받는 것 예: 분석 단위가 유저일 때, 내가 “친구 추천” 서비스를 받았을 때, 내가 추천된 사람에게 친구 신청을 보내고, 그 친구 신청을 받은 사람이 수락한다고 하자. 그 때, 두 사람 모두 친구가 생긴다. [발표자가 추가로 생각해본 내용] AB 테스팅 상황이라고 생각한다면, 내가 treatment 그룹에 있고, 나로 인해 친구 신청을 받은 사람이 control group 에 있다면, outcome 이 친구 숫자라고..