Dashboard 에 AB 테스팅의 결과가 실시간으로 들어온다고 해봅시다. 실험이 좋지 않은 결과를 보이거나 충분히 좋은 결과를 보일 때, 실험을 멈춰도 괜찮을까요? 실험의 진행 시간이 늘어남에 따라서 비용이 증가하기 때문에, 실무에서는 실험을 일찍 멈추고 싶은 유인이 있습니다. 하지만, 실험의 통계적 유의성을 나타내는 지표인 p-value 가 원하는 alpha 값 이하일 때, 이를 멈추면 문제가 발생합니다.
제가 참고한 논문인 Johari et al. (2017, KDD) 의 "Peeking at A/B Test" 에서 이러한 상황이 문제가 되는 경우를 시뮬레이션을 통해서 보여줍니다. 논문의 figure 2 는 이러한 문제가 발생하는 상황을 보여줍니다.
100명이 AA test 를 하고, 최대 방문자수가 n 명 이라 할 때, 몇 명이 significant 한 결과를 얻고 일찍 실험을 종료할까요? 예를 들어, 논문의 figure 2 에서 alpha = 0.05 이고 최대 방문자수가 n=2500 일 때, 100명 중에 약 54명 정도가 실험을 일찍 종료합니다. 즉, 실제로는 동일한 분포의 두 그룹에 대해서 지속적으로 p-value 를 모니터링하는 경우 54%의 확률로 두 집단 간에 차이가 있다고 잘못 판단하게 됩니다 (false positive, 두 집단이 동일한데 다르다고 잘못 판단할 확률).
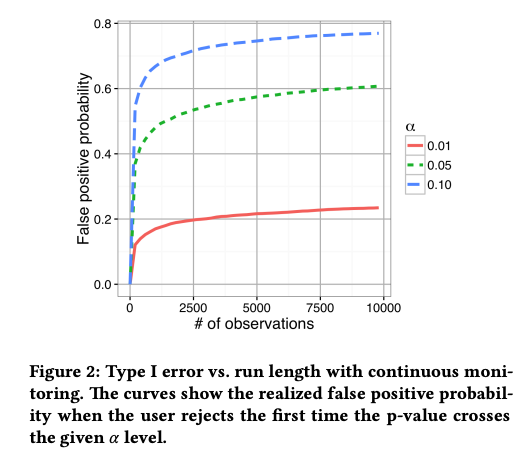
n=2500, alpha = 0.05 에 대한 시뮬레이션을 아래 코드와 같이 해보았습니다.
(구글 colab 링크에서 위의 코드를 실행해볼 수 있습니다. )
from scipy.stats.mstats_basic import Ttest_indResult
import numpy as np
from scipy import stats as st
# we need 100 simulation
# maximum number of simulation IS the x-axis in Figure 2. of Johari et al. (2017) KDD paper
maxSim = 2500
storageFP = [1] * 100
for s in range(100):
mu = 0
sigma = 1
p_val = 1
i = 1
grpA = []
grpB = []
pvals = []
grpA.extend([np.random.normal(mu,sigma)])
grpB.extend([np.random.normal(mu,sigma)])
while(p_val>0.05):
grpA.extend([np.random.normal(mu,sigma)])
grpB.extend([np.random.normal(mu,sigma)])
t_stat, p_val = st.ttest_ind(a=grpA, b=grpB, equal_var=True)
i = i+1
pvals.extend([p_val])
if i >maxSim:
storageFP[s]=0
breakdef Average(list):
return sum(list) / len(list)
average = Average(storageFP)
average저는 처음 해봤을 때는 false positive 값이 0.54가 나왔습니다 (두번째 했을 때는 0.6이 나오네요). maxSim 과 alpha 를 바꾸면서 해보면 figure 2 가 나오지 않을까 생각이 듭니다.
그런데, 문득 observation 이 하나씩 들어올 때마다 계속 p-value 를 확인한다는 것이 너무 극단적인 것이 상황이 아닌가 생각이 들었습니다 (자동화하지 않는 이상 매순간마다 모니터링하지는 않을 것이니까요). 2500 개 maximum observation 에 대해서, 500번에 한 번씩 (2500/5 = 500번) 5번 확인을 한다면, false positive 가 나올 확률은 어떻게 될까요?
from scipy.stats.mstats_basic import Ttest_indResult
import numpy as np
from scipy import stats as st
# we need 100 simulation
# maximum number of simulation IS the x-axis in Figure 2. of Johari et al. (2017) KDD paper
maxSim = 2500
storageFP = [1] * 100
for s in range(100):
mu = 0
sigma = 1
p_val = 1
i = 1
grpA = []
grpB = []
pvals = []
grpA.extend([np.random.normal(mu,sigma)])
grpB.extend([np.random.normal(mu,sigma)])
for j in range(maxSim):
if (p_val<=0.05 and (i==500 or i==1000 or i==1500 or i==2000 or i==2500)):
break
else:
grpA.extend([np.random.normal(mu,sigma)])
grpB.extend([np.random.normal(mu,sigma)])
t_stat, p_val = st.ttest_ind(a=grpA, b=grpB, equal_var=True)
i = i+1
pvals.extend([p_val])
if i >maxSim:
storageFP[s]=0
break
## average
def Average(list):
return sum(list) / len(list)
average = Average(storageFP)
average처음 구했을 때는 false positive 가 0.21 정도 나왔습니다. 두 번째 구할 때는 0.06이 나왔습니다. 세 번째는 0.09, 네 번째는 0.15, 다섯 번째는 0.18, 여섯 번째는 0.14, 일곱 번째는 0.18, 여덟 번째는 0.11 이 나오네요 (다음 번에는 시뮬레이션을 돌려보는게 더 좋을듯하네요).
제가 구한 값들의 평균을 내어보니 0.14 정도가 나옵니다.
해당 논문에서는 이러한 문제를 해결하면서 원하는 시점에 멈출 수 있는 통계치를 만들었습니다. Optimizely 에서는 이러한 보정된 값을 사용하는 것으로 보입니다. LRT (Likelihood-ratio test) 를 적용하는데, 어떻게 구하는지는 공부를 더 해봐야 할 것 같습니다.
애초에 문제가 발생하는 이유는 모니터링 결과에 따라서 관측치의 값을 정하기 때문입니다. 처음 미리 설정한 관측치값만큼 실험을 진행한다면 p-hacking 의 문제는 존재하지 않습니다. 그리고 모니터링의 빈도를 늘릴수록 false positive 의 확률이 증가한다는 사실을 염두해두는 것이 필요할 것 같습니다.
참고문헌
Johari, R., Koomen, P., Pekelis, L., & Walsh, D. (2017). Peeking at A/B Tests: Why it matters, and what to do about it. In ACM Conference on Knowledge Discovery and Data Mining (KDD).
'AB 테스팅 (온라인 실험)' 카테고리의 다른 글
| [책 A/B 테스트] (Ch05&6) "사이트 속도/지표" Trustworthy Online Controlled Experiments (0) | 2022.05.30 |
|---|---|
| [책 A/B 테스트] (Ch04) "실험 플랫폼과 문화" Trustworthy Online Controlled Experiments (0) | 2022.05.24 |
| [책 A/B 테스트] (Ch03) "실험 중 통계적 오류" Trustworthy Online Controlled Experiments (0) | 2022.05.23 |
| 샘플 사이즈 계산기의 공식 이해와 응용 (0) | 2022.05.09 |
| [책 A/B 테스트] (Ch02) "실험 수행과 분석" Trustworthy Online Controlled Experiments (0) | 2022.04.29 |