Ch10 . Complementary Techniques
요약
실험을 보완하기 위한 테크닉들로 "log-based analysis", "human evaluation", "user experience research (UER)", "focus groups", "survey", 그리고 "external data" 가 있다.
(1) log-based analysis: 실험을 분석하기 위해서 유저의 view, 행동이나 상호작용 들에 관한 지표를 구할 수 있다.
- 단점은 유저의 행동에 대한 자세한 이유를 이해하기 어렵다.
(2) human evaluation: 직접 사람을 고용해서 새로운 상품에 대한 반응을 수집한다.
- 단점은 고용된 사람들은 일반적인 유저와 다를 수 있다.
(3) user experience research (UER): eye-tracking (시선 트래킹)과 같은 기술이나 유저의 일기 등의 정보들을 통해서 유저에 관한 상세한 정보를 수집한다.
(4) focus groups: 피드백 형태의 질문이 가능하다. Open-ended 질문에 장점이 있다. 연구자의 질문에 대한 답변에 재질문이 가능한 장점이 있어보인다.
- 단점은 UER 스터디보다 적은 수의 표본이 채집된다. 그리고, 포커스 그룹의 선호가 일반적인 선호와 다를 수 있다.
(5) survey: 모집단에서 추출을 통해서 서베이를 실시한다.
- 단점은 survey bias 가 존재할 수 있다 (응답을 안 하는 사람이 발생함).
(6) external data: 다른 테크 리포트나 연구의 결과들과 비교한다.
- 단점은 다른 연구들의 자세한 background 를 모를 수 있다.
실험 결과와의 연관성을 잘 고려해야 한다.
어려운 개념이나 궁금했던 내용?
log-based analysis 가 A/B 테스팅을 보완한다고 했는데, 이전 챕터들에서 정의했던 CTR 같은 지표들은 log 이외의 정보들도 포함되기 때문에 log-based analysis 와 다른 것인가?
실무
메타 (구 페북)에서 survey scientist 를 고용하는 이유가 이러한 survey bias 같은 문제들 때문이 아닐까 싶다. 데이터가 많다고 해서 survey bias 문제가 해결되는 것은 아니기 때문에 주의가 필요할 것 같다.
Ch11 . Observational Causal Studies
요약
실험이 윤리적인 문제나 특수한 상황에서만 벌어지는 이벤트의 경우에는 observational study 를 할 수 있습니다. observational study 의 예로 interrupted time series, interleaved experiments, RDD, IV, PSM, DiD 가 있습니다.
(1) interrupted time series: 모형에 의해서 predict 된 outcome 과 실재 outcome 의 차이를 구합니다. (DiD 와 유사한 형태인데, control 그룹은 before period 에서의 원래 집단의 predicted 된 결과인 것 같네요)
(2) interleaved experiments: 랭킹 알고리즘에 사용됩니다.
(3) RDD: cutoff 기준으로 바로 앞전과 이후에 차이를 구한다. 사람들이 cutoff 를 몰라야 한다.
(4) IV: 랜덤하지만 treatment 와 연관된 변수를 찾아 random assignment 와 유사한 상황을 만든다.
(5) PSM: 관측가능한 변수들을 이용해서 propensity score 하나로 축약한 후에, score 가 유사한 treatment 그룹과 control 그룹을 묶는다.
(6) DiD: treatment 그룹과 control 그룹의 이전과 이후의 차이의 차이를 구한다.
각 분석 방법의 가정들이 분석하려는 상황에 부합하는지 잘 따져보아야 한다.
어려운 개념이나 궁금했던 내용?
interleaved experiments 두 집단 X 와 Y 를 mix 한다는 대목이 왜 그렇게 하는지 이해가 되지 않는다.
실무
observational case study 와 experiment 결과를 비교하는 리포트나 논문들을 참고하면 본인의 observational case study 의 신뢰도가 올라갈 것 같다.
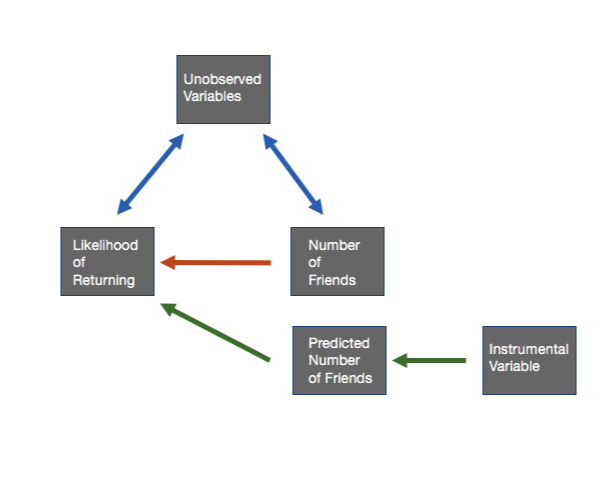
가설: Does having more friends on Twitch makes a user more likely to return to the site? (트위치에서 친구 한 명 더 있는 것이 유저 리텐션에 미치는 영향)
IV: 친구 추가를 권유하는 prompt (페북에 친구 추천이랑 비슷한 기능처럼 보인다) 를 randomize 한다.
First Stage (첫번째 테이블): control 그룹의 친구가 27명이라면, treatment 그룹은 control 그룹에 비해 약 2명 정도 더 많은 친구가 있었다 (IV 성공)
Second Stage (두번째 테이블): 친구가 0명일 때는 돌아올 확률이 23퍼센트이고, 한 명 더 친구가 생길 때마다 .075 퍼센트 만큼 리텐션 확률이 올라간다고 한다. 친구 추가 권유에 따른 효과는 친구가 약 2명 들어나니, 약 0.15 퍼센트의 리텐션 차이일듯하다. 평균적인 리텐션률이 대략 23 + 0.075 x 20 정도하면 24.5 퍼센트 정도인듯한데 그렇게 친구의 효과가 커보이지는 않는다.
PSM 관련 더 공부해볼 내용: Uber 의 uplifting 모델 관련 "elastic net". 구글링해보니 ESLR 에도 개념이 설명되어있는 것 같다.