Ch15 . Ramping Experiment Exposure: Trading Off Spped, Quality, and Risk
요약
모든 유저를 대상으로 실험을 하기보다는 점차적으로 개선책을 확대하는 것이 위험을 줄일 수 있습니다. 그렇다고 해서 개선책의 확대 속도가 느리면 그만큼 기업의 이익을 늘릴 수 없습니다. 장기적인 효과를 추정하는 것도 좋을 수 있으나, 개선된 프로덕트를 소비하지 못하는 유저가 생기는 것은 비윤리적일 수 있습니다. 첫 실험을 진행 중에 일부 유저 그룹을 남겨두는 것도 유용합니다. 너무 결과가 긍정적으로 나타나는 실험의 경우에는 추가 실험을 통해서 효과를 확인할 수 있기 때문입니다. 마지막으로, 실험이 완전히 마무리된 이후에는 실험을 위해 사용했던 코드를 정리할 필요가 있습니다.
어려운 개념이나 궁금했던 내용?
MPR 개념이 주석에 설명되어 있는데, 디테일한 내용을 이해할 필요가 있는지, 있다면 의미가 무엇인지 궁금하다. 그리고, Figure 15.1 의 그림에서 Pre-MPR 기간과 MPR 기간 간에 treatment 에 배정되는 비율이 다른 이유가 궁금하다. 내가 Pre-MPR 기간이 무엇인지 명확히 파악하지 못해서 그런 것 같기도 하다.
실무
유저 아이디가 해싱 (난해한 문자열화) 되고 그 문자열에 ADSWSDFK1, BWSDEYSM2 와 같은 패턴이 있다면, 첫번째 알파벳이 A,B 인 경우 treament 가 되는 UX 를 JavaScript 로 변화주는 형태로 실험을 진행할 수 있을 것 같기도 하다.
웹앱을 파이어베이스와 구글 옵티마이즈를 연동시켜 보았는데, treatment 되는 비율은 조정할 수 있는데, 날짜 기간을 내가 통제하지 못하는 것 같다. 그래도 지역도 도시 단위로 옵션이 존재한다.
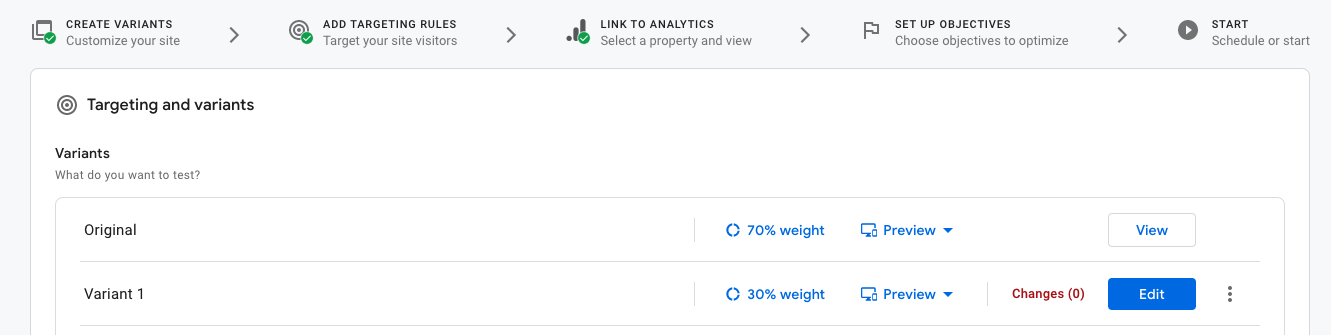
7:3 과 같은 비율로 실험도 가능하다.

샌프란시스코의 충성 고객을 타겟할 수 있다.
구글 옵티마즈의 타게팅 관련 문서 "Targeting Overview"
Ch16 . Scaling Experiment Analyses
요약
데이터를 프로세스하고 클리닝하는 작업이 필요합니다. 주요 지표에 대해 사전에 회사에서 동의할 필요가 있습니다. 실험 결과를 비분석 직군을 포함한 구성원들에게 요약해서 전달할 필요가 있습니다.
어려운 개념이나 궁금했던 내용?
Data computation 섹션에서 두 가지 방식 (책에서는 1. 과 2. 의 아이템으로 표시됨) 이 두리뭉술하게 이해가 된다. 첫번째는 주요 지표에 대한 descriptive statistic 에 가까운 역할로 보이고, 두 번째는 실험 결과와 관련된 지표에 관한 내용인가 싶었다.
실무
파이어베이스에 저장된 데이터 (로그 데이터는 제외)를 구글 BigQuery 로 불러온 후 이를 시각화까지 하는 방법에 대한 영상이 유용했다 (링크: https://www.youtube.com/watch?v=u9DfTl5yLLc). 아직, BigQuery 로 불러오는데까지 성공했다. 데이터 스튜디오로 전송이 가능하다.