4주차는 뉴럴 네트워크에 관한 내용입니다. 이번 단원에서는 직관적으로 뉴럴 네트워크의 이론을 이해하는 단원입니다. 저는 neural network 가 효율적으로 표현할 수 있는 non-linear 가설의 예시가 좋았습니다.
Neural network 를 벡터로 표현하기

where
and let
그리고,
where
예시
| Input | Output | ||
| 0 | 0 | 0 | |
| 0 | 1 | 1 | |
| 1 | 0 | 1 | |
| 1 | 1 | 0 | |
| 0 | 0 | 0 | ||
| 0 | 1 | 1 | ||
| 1 | 0 | 1 | ||
| 1 | 1 | 0 |
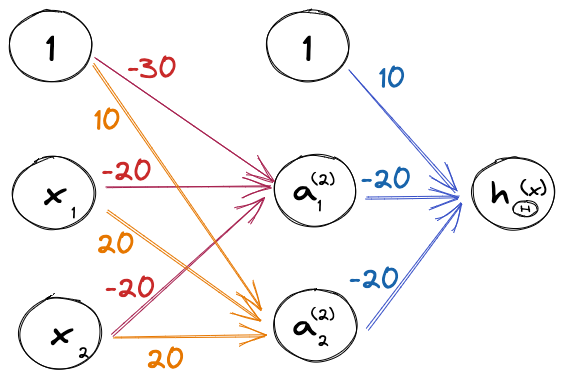
위 표의 빈칸에 맞는 값들을 찾아야 합니다.
| 0 | 0 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 | 0 |


종합하면, 아래 그림과 같다.
Multiclass Classification
개, 고양이, 사람, 자동차 등의 여러 가지 사물로 분류할 때는, output 을 개 = [1,0,0,0], 고양이 = [0,1,0,0], 사람 = [0,0,1,1], 자동차 = [0,0,0,1] 이런 식으로 정의하고 한 번에 하나씩 위의 방식으로 파라미터를 구합니다.
어플리케이션
손글씨에서 숫자 (0~9) 구하기와 같은 것들이 대표적입니다. 손글씨에서 숫자 구하기의 경우에는 10개의 y 를 [1,...,0] 이런 식으로 정의하고 구합니다. 파이썬 말고 C++ 에서도 동작하는 그러한 코드를 작성해보고 싶다 (파이썬 라이브러리보다 속도가 더 빠르지 않을까 싶네요).